Track Setting and Evaluation
We set up two tracks in the challenge for participants to investigate intelligent cockpit speech recognition with different limits on the scope of model size.
- Track I (Limited model size track): The number of model parameters cannot exceed 15M and the FST file of the system should be less than 25M if participants build a system with FST.
- Track II (Unlimited model size track): The number of model parameters is not limited.
Both of the tracks allow the participants to use the training data listed in the dataset section. The participants have to indicate the data used in the final system description paper and describe the data simulation scheme in detail.
The accuracy of the ASR system is measured by Character Error Rate (CER). The CER indicates the percentage of characters that are incorrectly predicted. For a given hypothesis output, it computes the minimum number of insertions (Ins), substitutions (Subs), and deletions (Del) of characters that are required to obtain the reference transcript. Specifically, CER is calculated by
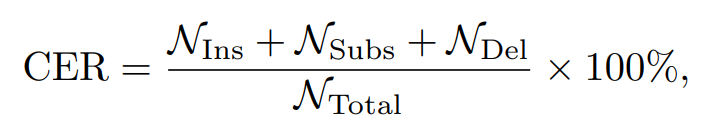
where NIns, NSubs, NDel are the character number of the three errors, and NTotal is the total number of characters. As standard, insertion, deletion, and substitution all account for the errors.







